欢迎光临广西法制网!
今天是 2025年07月02日 星期三
关注社会热点
一起实现我们的中国梦
原文标题:《比数据透视表更逆天,Excel 神技超级透视表来了!》
大家好,我是正在研究超级透视表的小爽~
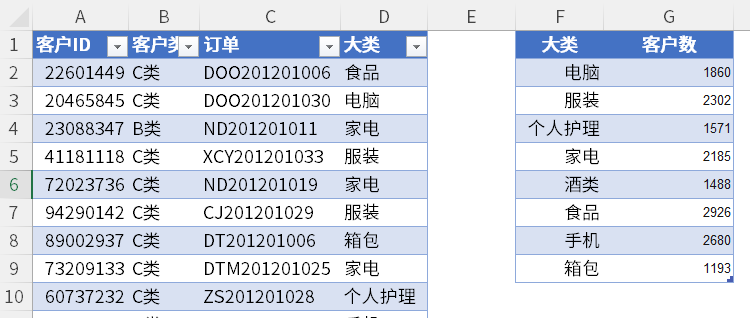
小 A 作为一位销售,每天都会收到当天的销售明细数据,然后他想要知道当天每个产品的客户数有多少,以便后面设计销售方案。
因为一个客户在当天可能对同个产品多次下单,而数据源中存在产品大类和客户 ID 字段,所以他需要根据产品大类对客户 ID 去除重复值,然后进行计数。
关于去除重复计数,Excel 中有一个很经典的用法,
是利用 SUMPRODUCT 和 COUNTIF/COUNTIFS 函数完成的。
=SUMPRODUCT(1/COUNTIF(统计区域统计区域))
针对这个问题,小 A 作为一个 Excel 函数高手,之前都是这么做的:
如下图,G2 单元格输入公式如下:
=SUMPRODUCT(IFERROR(1/COUNTIFS($A$2:$A$20001,$A$2:$A$20001,$D$2:$D$20001,F2)*EXACT($D$2:$D$20001,F2),0))
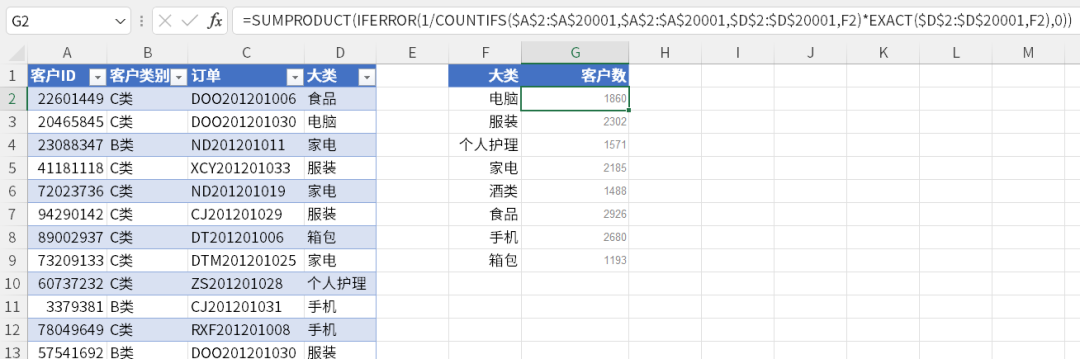
这样做可以是可以,不过一旦数量比较多,尤其是数组公式,表格就变得特别卡。
他知道,如果是 OFFICE 365,用 UNIQUE 函数和 FILTER 函数也可以做,但是公司用的不是 OFFICE 365。
公式如下:
=COUNTA(UNIQUE(FILTER($A$2:$A$20001,$D$2:$D$20001=F2)))
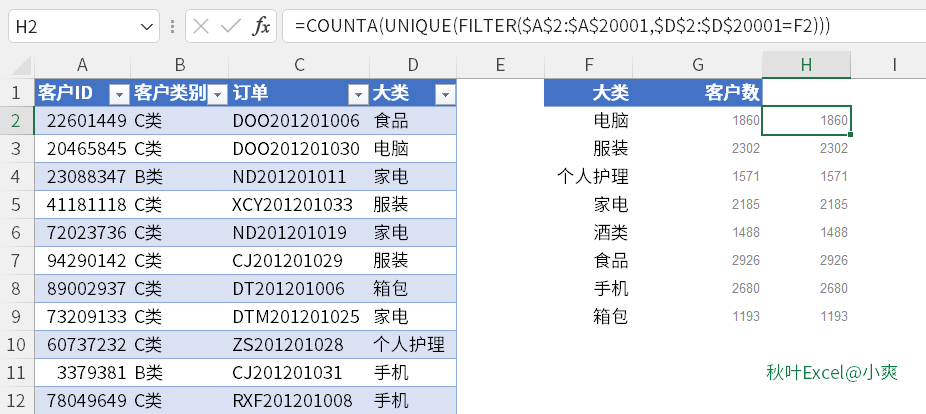
所以,小 A 就跑来问我,有没有更好的方法呢?
我:可以用超级透视表啊~
小 A:数据透视表我用过,超级透视表是啥??
我:这就带你看看超级透视表的世界!
1、非重复计数
我们先插入一个普通数据表。
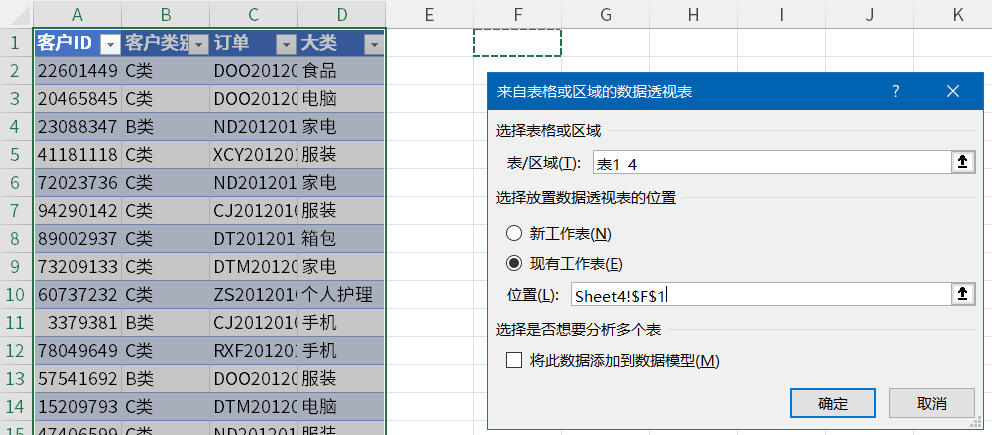
将大类拖拽到行区域,将客户 ID 拖拽搭配值区域。
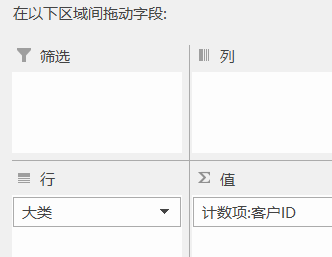
单击值区域其中一个单元格,鼠标右键-「值汇总依据」。
我们可以发现:值汇总区域是有非重复计数的,但是它是灰色的,不能选中使用。

那想要使用它的话,应该怎么办呢?
我们重新创建一个数据透视表,这次我们勾选「将此数据添加到数据模型」,把普通透视表变身成为超级透视表。
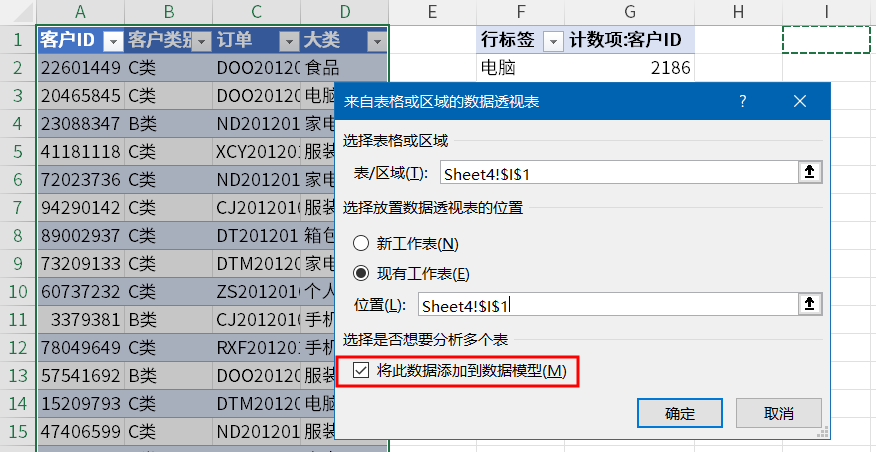
同样,我们将大类拖拽到行区域,客户 ID 拖拽到值区域。
单击值区域单元格-鼠标右键-值汇总区域,这里可以看到非重复计数功能现在可以使用了。
我们选择非重复计数。

此时我们可以看到非重复计数的结果已经出来了。

是不是很简单呢?
不需要复杂的数组公式,通过点点鼠标,我们就搞定了非重复计数。
作为一个补充,后面我来简单介绍一下这背后的计算原理,有兴趣的小伙伴可以继续往下瞧瞧。
2、知识拓展
如果你仔细观察,可能会发现一个问题。
我们对 ID 数据进行求和(红色边框内),结果为 16205,这时我们会发现结果与总计的值不一样。
这是什么缘故呢?难道是因为超级透视表(PowerPivot)出 bug 了?

要理解这个问题,我们需要了解超级数据透视表的度量值概念。
度量值:是数据分析中使用的计算。
包括使用数据分析表达式 (DAX) 公式创建的求和、平均值、最小值、最大值、计数或更高级的计算。
注:度量值的公式无论怎么编写,运算结果一定是个单值。
我们进入 Power Pivot 界面:
在 Power Pivot 选项卡中,单击【管理】,进入 PP 中。
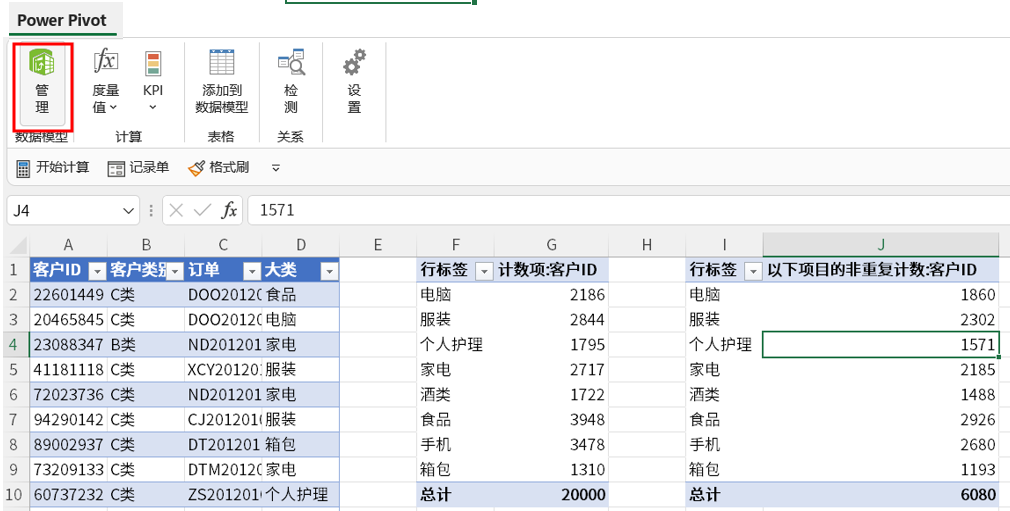
单击显示隐式度量值,我们可以看到:
我们刚刚使用的是汇总自带的隐性度量值,非重复计数,
它使用的 Dax 函数是 DISTINCTCOUNT 函数。
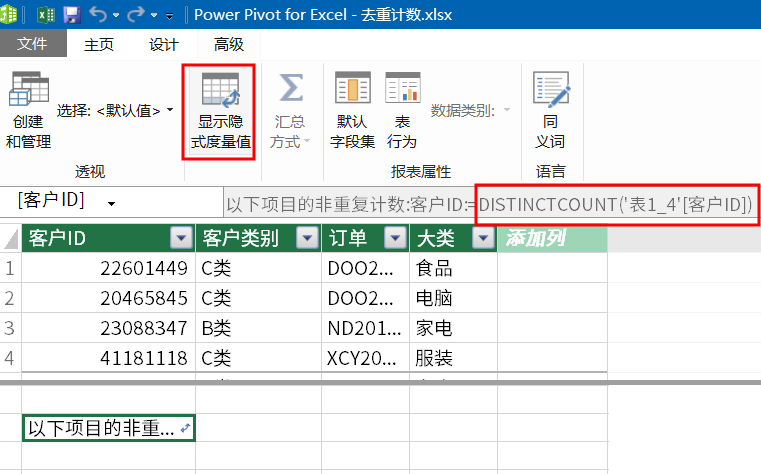
DISTINCTCOUNT 函数是用来统计去除重复后,唯一值的数量。参数结构如下:
=DISTINCTCOUNT(去除的列名,或者表名称)
如下图:
以电脑的数据为例(筛选环境为电脑)。
超级透视表的计算原理是:
先对数据表中大类列的电脑进行筛选,再针对筛选后所形成的表执行度量值公式:=DISTINCTCOUNT (表 [客户 ID]),也就是对客户 ID 进行非重复计数,结果为 1860。
同理,由于总计的数据没有筛选环境,所以 6080 是对整个数据表中的客户 ID 直接进行去重计数的结果。

因为一个客户 ID 可能同时买了别的产品大类,所以直接求和的数据(16205)一般会比总计的数据(6080)大。
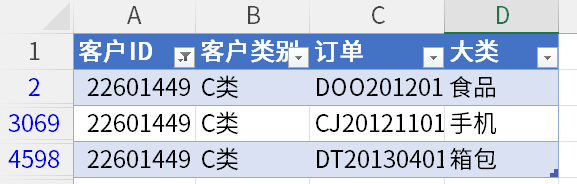
如下图:客户 ID22601449,同时购买了食品,手机,箱包。
总计直接去重的话,会直接把这三个订单当成一个订单。而直接求和的话,就是三个订单。
如果想要让总计中的数据,为大类中求和的数据结果,而不是总表客户 ID 去重的计数,我们就需要自己编写度量值了,这个如果有同学想知道的话,我们后面有机会再聊聊。
3、总结一下
本文介绍了数据透视表中的值汇总依据:非重复计数
❶ 普通数据透视表没有办法使用非重复计数。
❷ 超级透视表(Power pivot)可以使用非重复计数。









